
|
Grammar: Recognition |
|
The act of recognizing when a rule can be applied is to identify a subgraph within the host that matches with the graph depicted as the left hand side of the rule (as shown in Figure 1). Within a label rich system, the number of possible subgraphs reduces drastically. The labels within both the graph L and graph H in Figure 1 constrain the recognition to a single subgraph (node 2 and arc 10). However, if all of the labels are removed in L, then there are 16 possible subgraphs. The corollary that is adopted here is that the act of matching a node or arc to one in the host is that the labels must be a subset. In the case of Figure 1, the subgraph is recognized even though the matching location contains more labels than L. |
|
Figure 1: The recognition requires that we find the subgraph of the left hand side (a) of the rule within the host (b). In this example, nodes and arcs are referred to by the corresponding number, and labels for nodes and arcs are shown in parentheses. |
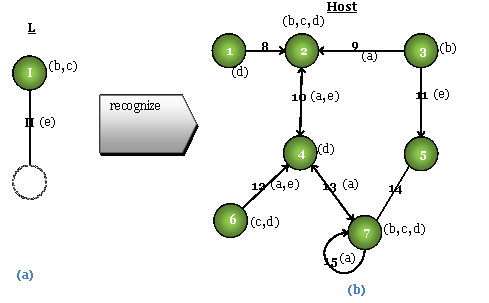
Subgraph BooleansFor creative systems, rules are likely constructed to model or contain particular heuristics or design rules. A label rich recognition like this can be interpreted as, “if a state of the design contains all the characteristics of a particular rule, then that rule is applicable.” However, there are cases when rules may not be easily represented by subsets of labels. It is for this reason that we additionally equip each node and arc within the left hand side graphs with a Boolean, containsAllLocalLabels. If this Boolean is set to true then we enforce that the set of labels must be identical in both rule and host. In this case, the rule shown in Figure 1 will not be recognized within the host. If all the labels were removed in the L graph, we would find only one location (node 5 and arc 14) as opposed to the 16 discussed above. It is clear from this example that by setting the label matching as “equal to” as opposed to subset, the number of recognized location reduces significantly. In addition to this restriction, there are number of additional Booleans that can be implemented to better capture the intended rule recognitions. For each node, one can limit the number of arcs that are connected to it. In our implementation, a Boolean called strictDegreeMatch is created. This essentially means that a node in a rule’s L will match only with a node in the host that has the same number of arcs connecting to it. In the preceding example of Figure 1 with the labels removed from L and the strictDegreeMatch set to true, there are only two locations that are properly matched (node 1 and arc 8, and node 6 and arc 12). For the arc we can provide an additional criteria on the direction of the arc with the Boolean, directionIsEqual. When this is set to false, we assume that undirected arcs can be matched with directed arcs or doubly-directed arcs in the host. When set to true, the Boolean limits matching undirected only with undirected, directed only with other directed with the same sense, and doubly-directed with doubly-directed. An additional Boolean related to arcs deals with handling the dangling nature of arcs. The L in Figure 1, only includes a single node and arc; however, many approaches to graph theory disallow arcs from having an unspecified or dangling end. In the development of the methodology and implementation presented here, both cases are handled. In the examples that have played out from Figure 3, the missing node at the bottom of L is treated as a wildcard that matches with any node regardless of its characteristics. If one creates a rule that seeks to match an arc to a similar dangling arcs in the host, then the Boolean, nullMeansNull can be set to true for the arc. This prevent this from matching with arcs that are defined between two nodes. In the example, this Boolean set to true would again prevent the rule from recognizing a legitimate subgraph with the host. Finally, the subgraph recognition ambiguities can result in the graph-wide Booleans, induced and spanning. A spanning subgraph is one that contains all the nodes of the host graph but not necessarily all the arcs. Clearly, this results in no recognition in the previous example. When the induced Boolean is set to true the subgraph is required to be an induced subgraph within the host. This means that L must contain all arcs that exist between the recognized nodes in the host. These subgraph Booleans are commonly accepted as fundamental to graph theory. Graphs can also have labels similar to those in the nodes and arcs. As a result, we create a final Boolean that relates to the global labels being a proper subset or equivalent to those in the host. A final summary of these subgraph Booleans are shown in Table 1. While some of these have existed before in past graph theory literature, we have expanded the set to include all possible ambiguities in what is meant by subgraph. Since a graph can be defined in category theory as an interacting set of sets (e.g. set of labels, sets of arcs, and sets of nodes) the Booleans allow us to independently define how the subsets are determined for each of these components. |
Recognition ProcedureOn the most general level this recognition takes two inputs: the L of a rule, and the host graph. What is expected as a result is a list of subgraphs where L is found in the host. For a particular rule and host, there may be no subgraph, one subgraph, or many subgraphs. These resulting subgraphs are often referred to as how L is mapped into the host. This becomes an important consideration for the application of a rule. The approach developed in our implementation is a recursive search starting with a single node in L. The first node in L is checked to see if it matches with each of the nodes in the host. For those in which it is a successful match, a modified depth-first-search (DFS) is invoked from each matching node within the host. As creators of the grammar rules, one can impact the efficiency of the recognition process by altering the order in which the nodes are presented. The computational structure for a graph stores the set of nodes as a list; by placing the most restrictive node (the node that is hardest to match) first in the list of nodes one can eliminate wasted search that would occur if a less restricted node is presented first. An example of this is shown in Figure 2. The node I in L is more restrictive than node III and the order of expansion is shown in Figure 2a and b. The depth-first-search proves to be a more efficient approach to recognition both in computational speed and memory. An additional item to note in these mappings is that locations including the same nodes and arcs are found multiple times. This is because our recognize-choose-apply requires that we uniquely match each node and arc to one in the host. This becomes more apparent in the discussion of rule application since the rule essentially includes individual instructions for each of the elements matched to the L graph. |
|
Table 1: A summary of the subgraph Booleans |
|
L |
|
(b, c, d) |
|
(a) |
|
II |
|
(d) |
|
(a) |
|
Rule Recognition I: matches with {2} and {7} |
|
Rule Recognition III: matches with {1}, {2}, {4}, {6}, and {7} |
|
(b) |
|
(c) |

|
Subgraph Boolean |
Applies to what aspect of rule |
when TRUE… |
|
spanning |
graph |
host contains an equivalent set of nodes as L |
|
induced |
graph |
host contains an equivalent set of arcs as L for the recognized set of nodes |
|
containsAllGlobalLabels |
graph |
host contains an equivalent set of global labels as L |
|
strictDegreeMatch |
node |
host node contains an equivalent set of arcs connected to it as L node (nodes have same degree) |
|
containsAllLocalLabels |
node |
host node contains an equivalent set of labels as L node |
|
containsAllLocalLabels |
arc |
host arc contains an equivalent set of labels as L arc |
|
directionIsEqual |
arc |
host arc has equivalent direction characteristics as L arc |
|
nullMeansNull |
arc |
host arc must be equivalently unconnected at ends as the L arc |